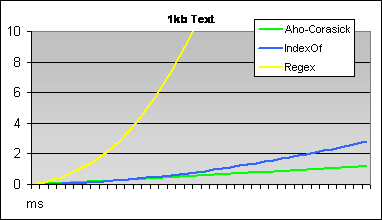
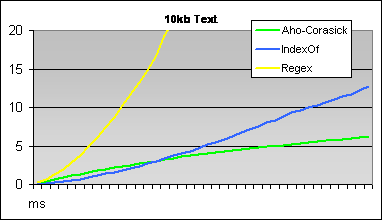
Sometimes when you need to debug a production bug which can't be replicated on a development machine its very useful to get the production database(s) on the development server.
Our infrastructure was rather complex since we used more than one database, one for each section of the software with a common database for the common data.
First, I needed a way of deleting a database with minimal resistance, so taking the database offline before deleting it assured 99% of the time that it will go through the deletion.
ALTER DATABASE [DBName_Development]
SET OFFLINE
WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [DBName_Development]
SET ONLINE
GO
DROP DATABASE [DBName_Development]
GO
Then I needed to backup the production database without affecting the backup set, hence the COPY_ONLY
BACKUP DATABASE DBName_Production
TO DISK = 'C:\TempBackup\DBName.bak'
WITH INIT,COPY_ONLY
GO
Then, we need to restore it on the development server, if the paths are a bit different the restore tsql needs some modifications, so this stored procedure was born:
-- =============================================
-- Author: Dror Gluska
-- Create date: 2010-05-30
-- Description: Restores databases with multiple files to specific destination
-- =============================================
CREATE PROCEDURE tuspTempRestoreDatabase
@backupfilename nvarchar(255),
@restorepath nvarchar(255),
@dbname nvarchar(255)
AS
BEGIN
Declare @LogicalName nvarchar(128)
Declare @PhysicalName nvarchar(128)
Declare @FType char(1)
Declare @FileId int
declare @dinfo table (LogicalName nvarchar(255),
PhysicalName nvarchar(255),
Type nvarchar(255),
FileGroupName nvarchar(255),
Size int,
MaxSize float,
FileId int,
CreateLSN int,
DropLSN int,
UniqueId uniqueidentifier ,
ReadOnlyLSN int,
ReadWriteLSN int,
BackupSizeInBytes int,
SourceBlockSize int,
FileGroupId int,
LogGroupGUID uniqueidentifier ,
DifferentialBaseLSN float,
DifferentialBaseGUID uniqueidentifier ,
IsReadOnly int,
IsPresent int,
TDEThumbprint int);
declare @sql nvarchar(4000);
set @sql = 'RESTORE FILELISTONLY from disk = ''' + @backupfilename + ''''
insert into @dinfo
execute sp_executesql @sql
set @sql = 'restore database ' + @dbname + ' from disk = ''' + @backupfilename + ''' with '
Declare c1 cursor for
select LogicalName,PhysicalName,Type,FileId
from @dinfo
order by Type
open c1
fetch next from c1
into @LogicalName,@PhysicalName, @FType, @FileId
while @@fetch_status = 0
begin
if(@FType = 'D')
begin
set @sql = @sql + char(9) + ' Move ''' + @LogicalName + ''' to ''' + @restorepath + '\' + @dbname + '_data_' + cast(@FileId as nvarchar(10)) + '.mdf''' + char(13)
end
else
begin
set @sql = @sql + char(9) + ' Move ''' + @LogicalName + ''' to ''' + @restorepath + '\' + @dbname + '_log_' + cast(@FileId as nvarchar(10)) + '.ldf''' + char(13)
end
fetch next from c1
into @LogicalName,@PhysicalName, @FType, @FileId
if (@@FETCH_STATUS = 0)
begin
set @sql = @sql + ',';
end
end
close c1
deallocate c1
print @sql
execute sp_executesql @sql
END
GO
Its asking for files list of the backup file, then writing a specific restore tsql with all these files to the selected directory name and the database name. here's an example:
exec tuspTempRestoreDatabase 'C:\TempBackup\DBName.bak', 'C:\Databases\DBName_Dev', 'DBName_Development'
As I stated before, this configuration had multiple databases, each held its own section but the tricky part was that it used cross databases stored procedures, function and views, so just restoring the databases with different names and location wouldn't do it as all cross referencing scripts would stop working.
The simplest solution I could find for it is go over all the scripts and modify the database names.
The first component of this stage is getting all the stored scripts and their bodies:
-- =============================================
-- Author: Dror Gluska
-- Create date: 2010-05-30
-- Description: Gets all Views/StoredProcedures and references outside the current database
-- =============================================
CREATE PROCEDURE tuspGetAllExecutables
AS
BEGIN
SET NOCOUNT ON;
declare @retval table (name nvarchar(max), text nvarchar(max), refs int);
declare @tmpval nvarchar(max);
declare @tmpname nvarchar(max);
declare @ref table(
ReferencingDBName nvarchar(255),
ReferencingEntity nvarchar(255),
ReferencedDBName nvarchar(255),
ReferencedSchema nvarchar(255),
ReferencedEntity nvarchar(255)
);
declare @refdata table (DBName nvarchar(255), Entity nvarchar(255), NoOfReferences int);
insert into @ref
select DB_NAME() AS ReferencingDBName, OBJECT_NAME(referencing_id) as ReferencingEntity, referenced_database_name, referenced_schema_name, referenced_entity_name
FROM sys.sql_expression_dependencies
insert into @refdata
select ReferencingDBNAme,
ReferencingEntity,
SUM(NoOfReferences) as NoOfReferences
from
(
select *
, (
select COUNT(*)
from @ref r2
where r2.ReferencedEntity = [@ref].ReferencingEntity
and r2.ReferencedDBName = [@ref].ReferencingDBName
)
as NoOfReferences
from @ref
) as refs
group by ReferencingDBNAme, ReferencingEntity
order by NoOfReferences
declare xpcursor CURSOR for
SELECT name
FROM syscomments B, sysobjects A
WHERE A.[id]=B.[id]
and xtype in ('TF','IF','P','V')
group by name
order by name
open xpcursor
fetch next from xpcursor into @tmpname
while @@FETCH_STATUS = 0
begin
set @tmpval = '';
select @tmpval = @tmpval + text
FROM syscomments B, sysobjects A
WHERE A.[id]=B.[id]
and A.name = @tmpname
order by colid
insert into @retval
select @tmpname, @tmpval, (select top 1 NoOfReferences from @refdata where [@refdata].Entity = @tmpname)
fetch next from xpcursor into @tmpname
end
close xpcursor
deallocate xpcursor
select * from @retval
order by refs
END
GO
Then, I needed a stored procedure that will give me all the indexes created on schemabound views (but it works on tables too):
-- =============================================
-- Author: thorv-918308
-- Create date: 2009-06-05
-- Description: Script all indexes as CREATE INDEX statements
-- Copied from http://www.sqlservercentral.com/Forums/Topic401795-566-1.aspx#bm879833
-- =============================================
CREATE PROCEDURE tuspGetIndexOnTable
@indexOnTblName nvarchar(255)
AS
BEGIN
--declare @indexOnTblName nvarchar(255) = 'test'
-- interfering with SELECT statements.
SET NOCOUNT ON;
--1. get all indexes from current db, place in temp table
select
tablename = object_name(i.id),
tableid = i.id,
indexid = i.indid,
indexname = i.name,
i.status,
isunique = indexproperty (i.id,i.name,'isunique'),
isclustered = indexproperty (i.id,i.name,'isclustered'),
indexfillfactor = indexproperty (i.id,i.name,'indexfillfactor')
into #tmp_indexes
from sysindexes i
where i.indid > 0 and i.indid < 255 --not certain about this
and (i.status & 64) = 0 --existing indexes
--add additional columns to store include and key column lists
alter table #tmp_indexes add keycolumns varchar(4000), includes varchar(4000)
--2. loop through tables, put include and index columns into variables
declare @isql_key varchar(4000), @isql_incl varchar(4000), @tableid int, @indexid int
declare index_cursor cursor for
select tableid, indexid from #tmp_indexes
open index_cursor
fetch next from index_cursor into @tableid, @indexid
while @@fetch_status <> -1
begin
select @isql_key = '', @isql_incl = ''
select --i.name, sc.colid, sc.name, ic.index_id, ic.object_id, *
--key column
@isql_key = case ic.is_included_column
when 0 then
case ic.is_descending_key
when 1 then @isql_key + coalesce(sc.name,'') + ' DESC, '
else @isql_key + coalesce(sc.name,'') + ' ASC, '
end
else @isql_key end,
--include column
@isql_incl = case ic.is_included_column
when 1 then
case ic.is_descending_key
when 1 then @isql_incl + coalesce(sc.name,'') + ', '
else @isql_incl + coalesce(sc.name,'') + ', '
end
else @isql_incl end
from sysindexes i
INNER JOIN sys.index_columns AS ic ON (ic.column_id > 0 and (ic.key_ordinal > 0 or ic.partition_ordinal = 0 or ic.is_included_column != 0)) AND (ic.index_id=CAST(i.indid AS int) AND ic.object_id=i.id)
INNER JOIN sys.columns AS sc ON sc.object_id = ic.object_id and sc.column_id = ic.column_id
where i.indid > 0 and i.indid < 255
and (i.status & 64) = 0
and i.id = @tableid and i.indid = @indexid
order by i.name, case ic.is_included_column when 1 then ic.index_column_id else ic.key_ordinal end
if len(@isql_key) > 1 set @isql_key = left(@isql_key, len(@isql_key) -1)
if len(@isql_incl) > 1 set @isql_incl = left(@isql_incl, len(@isql_incl) -1)
update #tmp_indexes
set keycolumns = @isql_key,
includes = @isql_incl
where tableid = @tableid and indexid = @indexid
fetch next from index_cursor into @tableid,@indexid
end
close index_cursor
deallocate index_cursor
--remove invalid indexes,ie ones without key columns
delete from #tmp_indexes where keycolumns = ''
--3. output the index creation scripts
set nocount on
--create index scripts (for backup)
SELECT
'CREATE '
+ CASE WHEN ISUNIQUE = 1 THEN 'UNIQUE ' ELSE '' END
+ CASE WHEN ISCLUSTERED = 1 THEN 'CLUSTERED ' ELSE '' END
+ 'INDEX [' + INDEXNAME + ']'
+' ON [' + TABLENAME + '] '
+ '(' + keycolumns + ')'
+ CASE
WHEN INDEXFILLFACTOR = 0 AND ISCLUSTERED = 1 AND INCLUDES = '' THEN ''
WHEN INDEXFILLFACTOR = 0 AND ISCLUSTERED = 0 AND INCLUDES = '' THEN ' WITH (ONLINE = ON)'
WHEN INDEXFILLFACTOR <> 0 AND ISCLUSTERED = 0 AND INCLUDES = '' THEN ' WITH (ONLINE = ON, FILLFACTOR = ' + CONVERT(VARCHAR(10),INDEXFILLFACTOR) + ')'
WHEN INDEXFILLFACTOR = 0 AND ISCLUSTERED = 0 AND INCLUDES <> '' THEN ' INCLUDE (' + INCLUDES + ') WITH (ONLINE = ON)'
ELSE ' INCLUDE(' + INCLUDES + ') WITH (FILLFACTOR = ' + CONVERT(VARCHAR(10),INDEXFILLFACTOR) + ', ONLINE = ON)'
END collate database_default as 'DDLSQL'
FROM #tmp_indexes
where left(tablename,3) not in ('sys', 'dt_') --exclude system tables
and tablename = @indexOnTblName
order by tablename, indexid, indexname
set nocount off
drop table #tmp_indexes
END
And finally I needed something to connect those two components into a solution:
declare @codetext nvarchar(max);
declare @newcodetext nvarchar(max);
declare @idxcode nvarchar(max)
declare @tablename nvarchar(255);
declare @indextable table (DDLSQL nvarchar(max));
--get all executables
declare @executables table(name nvarchar(max), text nvarchar(max),refcount int);
insert into @executables
exec tuspGetAllExecutables
declare spcursor CURSOR for
select text,name
from @executables
order by refcount
open spcursor
fetch next from spcursor into @codetext, @tablename
--for each executable
while @@FETCH_STATUS = 0
begin
set @newcodetext = @codetext;
--modify the database name
set @newcodetext = REPLACE( @newcodetext,'DBName_Production.','DBName_Development.')
--etc' etc' etc'
--check if we actually modified the contents of the script, otherwise, no need to alter it.
if (@newcodetext != @codetext)
begin
--modify CREATE to ALTER
set @newcodetext = REPLACE( @newcodetext,'CREATE FUNCTION','ALTER FUNCTION')
set @newcodetext = REPLACE( @newcodetext,'CREATE PROCEDURE','ALTER PROCEDURE')
set @newcodetext = REPLACE( @newcodetext,'CREATE VIEW','ALTER VIEW')
--get all indexes on script, if its a schemabound view, it will get all the indexes on that view, otherwise empty
insert into @indextable
exec tuspGetIndexOnTable @tablename
print @tablename
print @newcodetext
EXECUTE sp_executesql @newcodetext
--recreate lost index for schemabinded views
if (select COUNT(*) from @indextable) > 0
begin
declare vidxcursor cursor for select DDLSQL from @indextable
open vidxcursor
fetch next from vidxcursor into @idxcode
while @@FETCH_STATUS = 0
begin
print @idxcode
EXECUTE sp_executesql @idxcode
fetch next from vidxcursor into @idxcode
end
close vidxcursor
deallocate vidxcursor
end
end
fetch next from spcursor into @codetext, @tablename
end
close spcursor
deallocate spcursor
In the end, I needed to delete user emails from the databases so test won't cause the application to start emailing users, but you might have your own development practices.
And finally:
print 'Done!'